Regroupement des occurrences
Il peut y avoir des doublons dans l’index GBIF. Certains enregistrements peuvent avoir la même date, le même nom scientifique, le même numéro de catalogue et le même emplacement, mais provenir de deux éditeurs différents ou présenter des attributs légèrement différents.
Il existe de nombreuses raisons valables pour lesquelles ces doublons apparaissent sur GBIF. Parfois une observation a été enregistrée dans deux systèmes différents, parfois plusieurs enregistrements correspondent à des doublons d’herbiers (vous pouvez consulter les travaux de Nicky Nicolson sur le sujet), parfois un spécimen a été numérisé deux fois, parfois un enregistrement a été enrichi d’informations génétiques et republié via une plateforme différente…
C’est pourquoi nous avons lancé une fonctionnalité expérimentale de regroupement des données visant à identifier sur GBIF les enregistrements potentiellement rattachés. Le but était non seulement de trouver les doublons potentiels, mais aussi de trouver des liens intéressants, par exemple entre les enregistrements de typification ou les enregistrements qui proviennent de collections d’histoire naturelle, les séquences dérivées de l’ADN et les citations de matériaux examinés lors de la publication de traitements taxonomiques dans des articles de revues.
Les enregistrements inclus dans un groupe peuvent être trouvés avec le filtre « is in the cluster » dans la recherche d’occurrences. Chaque page d’occurrence qui fait partie d’un groupe aura un onglet "GROUPE" qui affiche les enregistrements potentiellement rattachés (voir une capture d’écran de cet exemple ci-dessous).
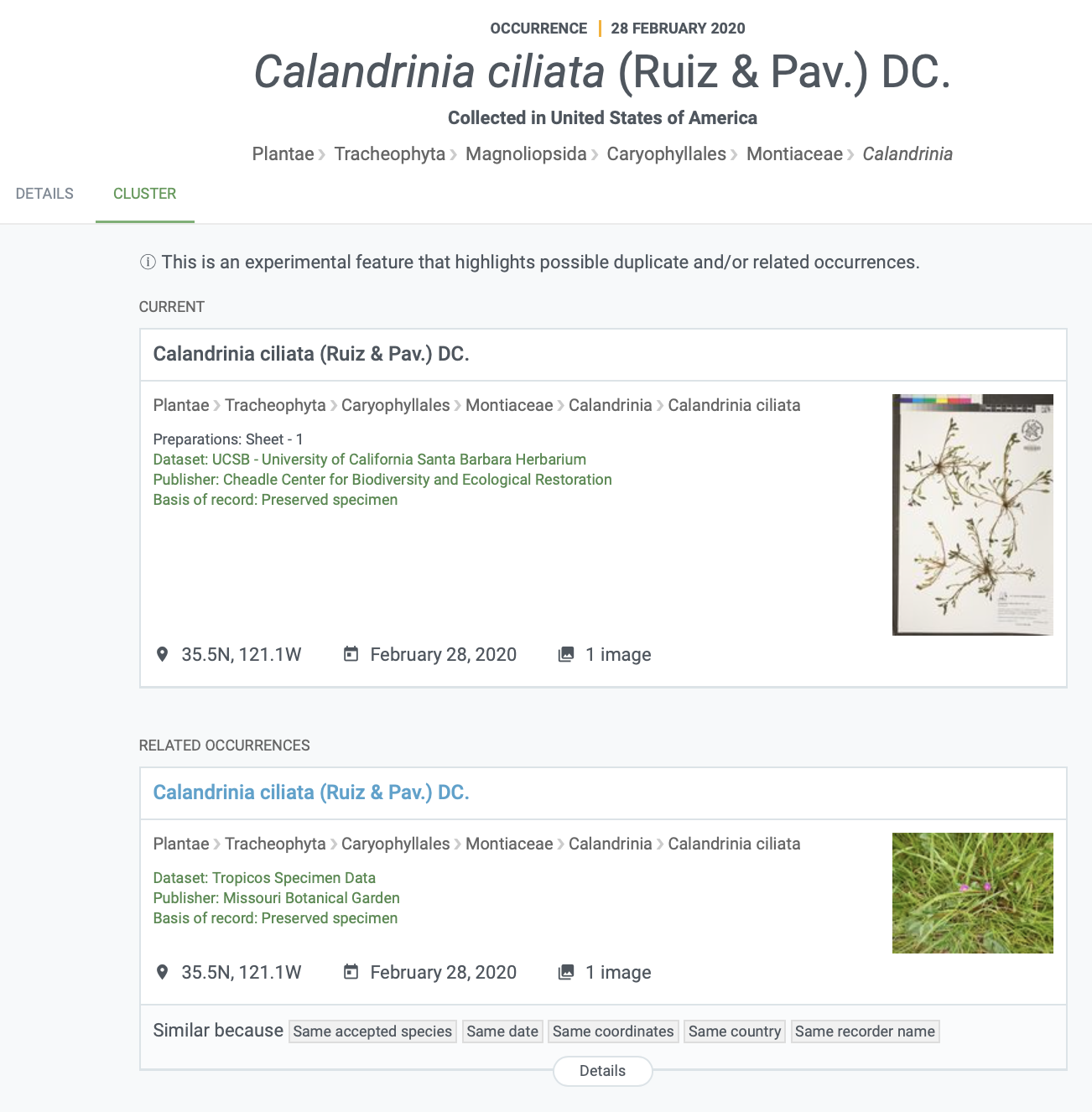
Vous pouvez lire cette nouvelle pour plus d’informations et quelques exemples intéressants.
Regroupements des enregistrements
Étape 1 : Sélectionner les candidats
La comparaison de presque 2 milliards d’enregistrements entre eux exige beaucoup de ressources et s’avère peu pratique. La première étape du processus de regroupement des données consiste donc à sélectionner et à grouper les enregistrements candidats à comparer.
To help avoid dubious connections, only records matched to a species or a more specific rank in the taxonomic backbone are eligible for clustering. Similarly, records flagged as being matched to a higher taxon are excluded.
For the remaining eligible records, the system first creates a series of "hashes" based on specified fields. All records sharing a hash are candidates to compare against each other.
Par exemple, l’un des « hachages » utilisés est basé sur la clé d’espèce, les coordonnées arrondies, l’année, le mois et le jour. Cela signifie que les enregistrements qui partagent les mêmes valeurs pour ces champs seront regroupés dans le tableau des candidats pour un examen plus approfondi.
Les champs utilisés pour identifier et grouper les candidats sont un sous-ensemble de ce qui sera utilisé ultérieurement pour les comparer (voir le tableau ci-dessous). Voir le code source pour vérifier les détails.
Étape 2 : Comparer et évaluer
Dans cette deuxième phase, le système comparera tous les enregistrements dans l’ensemble des candidats entre eux et générera des assertions. Les assertions sont examinées et l’algorithme décide s’il y a suffisamment de preuves dans les assertions pour créer un lien entre elles.
Le tableau ci-dessous résume la manière dont ces assertions sont formulées, mais pour plus d’informations, vérifiez le code source.
| Assertion | Champs vérifiés | Condition vérifiée |
|---|---|---|
Même spécimen |
|
même taxonKey entre enregistrements et typeStatus est « Holotype » pour les deux enregistrements |
Relation de typification |
|
même entre enregistrements |
Mêmes espèces acceptées |
|
même entre enregistrements |
Même date |
|
même entre enregistrements |
Date approximative |
|
dates à un jour d’intervalle |
Date différente |
|
diffère entre enregistrements |
Date non conflictuelle |
|
aucune date sur aucun des deux enregistrements |
Même nom d’enregistreur |
|
même entre enregistrements |
Même coordonnées |
|
même entre enregistrements |
Coordonnées non conflictuelles |
|
aucune coordonnée sur un ou les deux côtés |
À moins de 200 m |
|
distance ≤ 0,200km |
À moins de 2 km |
|
distance ≤ 2,00km |
Même pays |
|
même entre enregistrements |
Pays non conflictuel |
|
pays uniquement sur un seul enregistrement |
Pays différent |
|
diffère entre enregistrements |
Identifiants se chevauchent |
|
vérifie tou chevauchement d’identifiants entre les enregistrements |
Autres numéros de catalogue qui se chevauchent |
|
vérifie si l’autre numéro de catalogue correspond au code de l’institution, au code de la collection et au numéro de catalogue d’un autre enregistrement |
Provient du référentiel de séquences |
|
vérifie si l’une des datasetKey correspond à l’un des ensembles de données du référentiel de séquences : séquences INSDC, organismes hôtes INSDC, échantillons environnementaux INSDC, iBOL (voir les clés |
Sont des spécimens |
|
vérifie si la base d’enregistrement des deux enregistrements est l’une des suivantes : |
Le tableau ci-dessous résume les combinaisons des assertions qui sont suffisants pour lier les enregistrements dans un groupe. Si un groupe d’occurrences partage les combinaisons des assertions pour une colonne donnée, elles seront regroupées.
| Assertion | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Même spécimen |
x |
|||||||||||||
Relation de typification |
x |
|||||||||||||
Mêmes espèces acceptées |
x |
x |
x |
x |
x |
x |
x |
x |
x |
x |
||||
Même date |
x |
x |
x |
x |
||||||||||
Date non conflictuelle |
x |
x |
x |
x |
||||||||||
Date approximative |
x |
x |
||||||||||||
Même coordonnées |
x |
x |
x |
|||||||||||
Coordonnées non conflictuelles |
x |
x |
||||||||||||
À moins de 200m |
x |
x |
||||||||||||
À moins de 2km |
x |
x |
x |
|||||||||||
Identifiants se chevauchent |
x |
x |
x |
x |
x |
x |
||||||||
Autres numéros de catalogue qui se chevauchent |
x |
|||||||||||||
Même nom d’enregistreur |
x |
x |
||||||||||||
Provient du référentiel de séquences |
x |
|||||||||||||
Sont de spécimens |
x |
Tout groupe d’occurrences associé à l’assertion Different date ou Different country ne sera pas regroupé.
|
Pourquoi certaines occurrences ne sont-elles pas regroupées ?
Il est possible que certaines occurrences partagent l’une des combinaisons d’assertions, mais ne soient pas encore affichées comme regroupées. Cela peut s’expliquer par plusieurs raisons :
-
Les occurrences viennent d’être publiées. En ce moment, le processus de regroupement exige beaucoup de ressources et ne s’exécute pas automatiquement. Nous devons le déclencher manuellement. Cela signifie qu’il peut s’écouler plusieurs semaines avant que les occurrences nouvellement publiées soient regroupées.
-
Les « doublons » proviennent du même ensemble de données. L’algorithme de regroupement compare uniquement les occurrences entre les ensembles de données, et non au sein d’un même ensemble de données.
-
Il peut y avoir un retard entre le moment où les occurrences sont regroupées et celui où elles deviennent consultables avec le filtre « is in cluster » (cela est dû à quelques raisons techniques trop longues à expliquer dans ce post, mais liées à la mise à jour des index de recherche séparément du tableau de regroupement)
Il peut y avoir d’autres raisons imprévues. En cas de doute, veuillez nous contacter à l’adresse helpdesk@gbif.org.
Améliorer les liens
Si, pour une raison ou une autre, vous devez publier sur GBIF des occurrences pour des observations ou des spécimens dont vous savez qu’ils figurent déjà sur GBIF, comment procéder au mieux ?
-
Assurez-vous que vous réutilisez les mêmes identifiants autant que possible, y compris la mise en forme. Les mêmes numéros de catalogue, occurrenceID, etc.
-
Utiliser le associatedOccurrences terme et l’extension de la relation de ressources. Ils ne sont pas utilisés aujourd’hui dans le cadre du regroupement, mais devraient l’être à l’avenir. Ils constituent aussi le moyen approprié pour communiquer les liens au sein de Darwin Core.